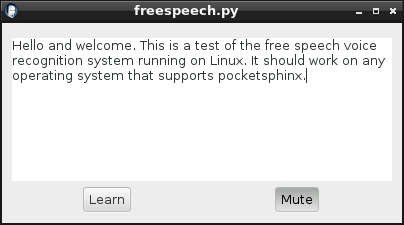
About
FreeSpeech is a free and open-source (FOSS), cross-platform desktop application front-end for PocketSphinx realtime speech recognition, dictation, transcription, and voice-to-text engine. FreeSpeech adds a Learn button to PocketSphinx, simplifying the complicated process of building language models. Get FreeSpeech via git from Github.
New Experimental version for Python3, Gtk3, and Gstreamer1.0.//github.com/themanyone/freespeech-vr/tree/python3
In addition to dictation, FreeSjpeech now provides voice commands and keyboard emulation, so users can dictate into other apps, remote terminals, and virtual machines.
Install Dependencies
Windows
Installation should work with the gstreamer sdk, which also contains pygtk2 and gstreamer-python. Unfortunately, compiling sphinxbase, pocketsphinx, and the pocketsphinx python module with VS2010 and SWIG is a non-trivial exercise for new Windows developers. We are working on an instructable...
- VS2010 + www.dreamspark.com/Product/Product.aspx?productid=4
- Install Python 2.7 www.python.org/downloads/
- get pocketsphinx and sphinxbase from github.com/cmusphinx
- Get Winrar https:www.rarlab.com/download.htm
- Install git for Windows.
- Create a folder, e.g. c:\dev
- Clone sphinxbase and pocketsphinx from github and put them in \dev
- Open the .sln files in each folder and build projects
- Install SWIG.
- Build Python module.
Linux/Cygwin
The following packages should be installed through the package manager.
Fedora
su -c 'yum groupinstall "C Development Tools and Libraries"'
su -c 'yum -y install gstreamer-python sphinxbase-libs \
pocketsphinx-libs pocketsphinx sphinxbase pocketsphinx-plugin \
python-simplejson python-xlib pygtk2 git'Ubuntu
Open a terminal and install the pocketsphinx repository:
sudo add-apt-repository ppa:dhuggins/cmusphinxEnter password and press Enter twice.
Get updates and install dependencies.
sudo apt-get update
sudo apt-get python-xlib python-simplejson python-gtk2 python-gst0.1 \
gstreamer0.10-pocketsphinx sphinx-common python-sphinxbase \
python-pocketsphinx sphinxbase-utils gitIf installation balks and says it can't find /media/cdrom the location may be different. The trick is to use the mount command from a terminal to discover where the cd is mounted and make it a link to /media/cdrom
sudo ln -s (location, change this) /media/cdromTest
Before we begin, load pavucontrol, Audacity (or some other audio recording program that has a recording monitor) and check sound levels. Users should be able to record and play back audio.
arecord temp.wav -r 16000
aplayTest pocketsphinx
pocketsphinx_continuousSay something. (It should print lots of spam while doing some (very basic) speech recognition). Pocketsphinx is the "back-end" for FreeSpeech and does all the work in the background. FreeSpeech merely provides a graphical user interface and simplifies working with word frequency, dictionary, and language files.
Install FreeSpeech and Language Tools
Download CMU-Cam_Toolkit_v2 and unpack it. Read the instructions in the README and edit the Makefile. To summarize, most PC hardware is what they call "little-endian" and it requires this change: Edit CMU-Cam_Toolkit_v2/src/Makefile and remove the # sign in front of this line:
BYTESWAP_FLAG = -DSLM_SWAP_BYTESRun make to build the tools.
cd CMU-Cam_Toolkit_v2/src
makeManually copy the tools from ../bin to somewhere in $PATH like: /usr/local/bin
sudo cp ../bin/* /usr/local/bin/The tools expect to write to /usr/tmp
sudo ln -s /tmp /usr/tmpLanguage files and preferences are copied to /home/$USER/.config but the location may be changed by changing or adding the environment variable, $XDG_CONFIG_HOME
export XDG_CONFIG_HOME=$HOME/.configGet FreeSpeech using git. (Install git from the Software Center if necessary.)
cd ~/Downloads
git clone //github.com/themanyone/freespeech-vr.gitUsing FreeSpeech
There is no desktop icon yet. Right-click on the desktop to create one. Launching the program may be done via the Python interpreter.
cd ~/Downloads/frees*
python freespeech.pyPosition the microphone somewhere near enough and begin talking. To end of the sentence, say "period" (or "colon", "question-mark", "exclamation-point") Look at the dictionary, "custom.dic" for ideas.
Voice commands are included. A list of commands pops up at start-up or say "show commands" to show them again. The following voice commands are supported (except only "scratch that" is available when using X keyboard emulation).
- file quit - quits the program
- file open - open a text file in the editor
- file save (as) - save the file
- show commands - pops up a customize-able list of spoken commands
- editor clear - clears all text in the editor and starts over
- delete - delete [text] or erase selected text
- insert - move cursor after word or punctuation example: "Insert after period"
- select - select [text] example: "select the states"
- go to the end - put cursor at end of document
- scratch that - erase last spoken text
- back space - erase one character
- new paragraph - equivalent to pressing Enter twice
Troubleshooting
Prior to blaming freespeech, make sure audio recording and pocksphinx works. Run pocketsphinx_continuous from the command line in a terminal window and make sure that it works. If not, check your pocketsphinx installation. We regret that we are not affiliated with pocketsphinx and do not have the resources to support it.
In case of messages like this:
Trouble writing /home/*/.config/FreeSpeech/freespeech.idngram
Trouble writing...It usually means nobody installed CMU-Cambridge Statistical Language Modeling Toolkit v2 or there is a problem with the tools themselves. Edit the Makefile and follow the instructions therein before running make. Manually copy the files in the bin directory somewhere in your $PATH like /usr/local/bin on Linux or C:\windows\system32 on Windows.
For some reason, the toolkit expects to be able to write to /usr/tmp. The tmpfile() function uses the P_tmpdir defined in <stdio.h>, but the Makefile installs everything under /usr. The quick-fix is to provide /usr/tmp for machines that don't have it.
sudo ln -s /tmp /usr/tmpImproving accuracy
The biggest improvements in accuracy have been achieved by adjusting the microphone position. The volume level and microphone selection may be found using pavucontrol. Also try making a recording with Audacity and checking the noise levels to make sure it sounds like intelligible speech when played back.
Adapt PocketSphinx to a particular voice or accent for better accuracy. See https:cmusphinx.sourceforge.net/wiki/tutorialadapt
Language corpus
The language corpus that ships with this download, "freespeech.ref.txt" is likely to be very limited. Our excuse is that the small size saves memory while providing room to learn spoken grammar. Don't be surprised if it does not work very well at first. Use the keyboard to manually edit the text in the box until it says what was intended to say. Then hit the "Learn" button. It will try to do better at understanding next time! One may also train personalized grammar by pasting in gobs of text from previously authored websites and documents.
It seems that the PocketSphinx folks were trying to add support for capitalized words. If there is a word like "new" in the dictionary which could also be capitalized, as in "New Mexico" it is enough to make a capitalized copy like so:
new N UW
New N UWNow train the new grammar, by using the capatalized form in a few sentences and pressing the Learn button. PocketSphinx will henceforth decide the capitalization depending on the context in which it appears. We tested it and it works! It capitalizes words like "New Mexico" and "The United States of America" but does not capitalize "altered states" nor "new pants". This is a wild idea, but maybe we could make a dictionary containing both capitalized and un-capitalized words. That would save us the effort of going through and capitalizing all the proper names. The only question is would the resulting dictionary be too big? The solution is probably to propose a patch to make make PocketSphinx ignore case in the dictionary, using the capatalization as it is found in the corpus, not the dictionary.
Don't worry if PocketSphinx learns bad grammar. It's not strictly necessary, but our corpus file, "lm/freespeech.ref.txt" may be manually corrected if it develops poor speech habits. Changes will apply next time anybody presses the "Learn" button.
The language model may be further tweaked and improved.
Dictionary
If there is a word that it stubbornly refuses to recognize, even after teaching it with several sentences, edit the dictionary: "freespeech.dic"
Sometimes the dictionary pronunciation can be little bit off. Notice that some other words have alternate pronunciations denoted with (2). Go ahead and change the pronunciation or add an alternate and see if it doesn't improve immediately the next time the program starts.
This dictionary is based on Pocketsphinx's cmu07a.dic because it contains punctuation, such as ".full-stop" and "?question-mark"). See "freespeech.dic" for the list of punctuation and their pronunciations. Adding new words to the dictionary may be done manually, along with their phonetic representation, but we are working on incorporating a word trainer.
About the CMU Pronouncing Dictionary https:www.speech.cs.cmu.edu/cgi-bin/cmudict
=Security and privacy=FreeSpeech does not send any information over the network. Speech recognition is done locally using pocketsphinx. Learned speech patterns are stored in "plain text" format in "$HOME/.config/FreeSpeech/freespeech.ref.txt". Although the file should not be accessible to other users, it is nevertheless good practice not to teach FreeSpeech sensitive or private information like passwords, especially if others share access to the PC.
Keep it going.Support development or hire an expert programmer for your next project.
 Copyright © 2026 Henry Kroll III, thenerdshow.com This web page is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.
Copyright © 2026 Henry Kroll III, thenerdshow.com This web page is licensed under a Creative Commons Attribution-ShareAlike 3.0 Unported License.